


一、软件说明 这个声音克隆工具,可使用任何人类音色,将一段文字合成为使用该音色说话的声音,或者将一个声音使用该音色转换为另一个声音。 使用非常简单,没有N卡GPU也可以使用,下载预编译版本,双击 app.exe 打开一个web界面,鼠标点点就能用。 支持 中文、英文、日语、韩语 4种语言,可在线从麦克风录制声音。 为保证合成效果,建议录制时长5秒到20秒,发音清晰准确,不要存在背景噪声。 英文效果比中文效果好。 二、使用方法 1、下载预编译版,适用于window 10/11(已含文字到语音模型,语音到语音模型需单独下载),Mac下请拉取源码自行编译。 【github下载】【百度网盘下载:提取码: hadx】 2、解压后进入解压目录,双击 start.bat ,等待自动打开web窗口。 3、输入文字或者上传想转换的音频文件,然后录制或从本地上传一段音色文件,开始转换 4、预编译版仅支持CPU,只包含文字到语音模型,如果需要语音到语音功能,即上传一个音频文件,然后将该音频转换为使用选定音色的另一个音频,需单独下载语音到语音(speech-to-speech)模型,然后放到和app.exe同级的tts文件夹中。 speech-to-speech模型下载:【百度网盘:提取码: g3w8】【github下载】 三、常见问题 1、启动后需要冷加载模型,会消耗一些时间,请耐心等待显示出http://127.0.0.1:9988, 并自动打开浏览器页面后,稍等两三分钟后再进行转换 2、如果打开的cmd窗口很久不动,需要在上面按下回车才继续输出,请在cmd左上角图标上单击,选择“属性”,然后取消“快速编辑”和“插入模式”的复选框 四、源码部署,以window为例
Tag: AI
基于AI,能无损分辨率去除图片/视频硬字幕、水印,无需申请第三方API,本地运行的软件。

一、它能做什么? video-subtitle-remover (VSR) 是一款基于AI技术,它能够通过AI算法模型,对去除字幕文本的区域进行填充(非相邻像素填充与马赛克去除),无损分辨率去除视频中的硬字幕,并支持自定义字幕位置(传入位置)和自动去除所有字幕的软件(不传入位置)。 项目开源地址:https://github.com/YaoFANGUK/video-subtitle-remover 二、硬件要求: GPU:GTX 1060或以上显卡(目前暂不支持Nvidia以外的显卡) CPU: 支持AVX指令集 三、使用说明:直接下载压缩包解压运行,仅支持Nvidia显卡。 Windows GPU版本v1.0.0(GPU): 百度网盘: vsr_windows_gpu_v1.0.0.7z 提取码:vsr1 Google Drive: vsr_windows_gpu_v1.0.0.7z
无需配置,无需安装,解压即用的AI人脸替换工具


无需配置,无需安装,解压即用。支持图片、视频人脸替换,支持支持CPU和GPU解码,而且效果还不错的AI人脸替换工具软件。
如何使用 DALL-E 3 创建 99.9% 一致风格形象的系列图片


使用 DALL-E 3 创建 99.9% 一致风格形象的系列图片。从单色插图到高级电影镜头能保持99.9% 一致风格形象的方法。
用群晖的Docker搭建可以支持Microsoft Azure的ChatGPT,并支持ChatGPT 4模式。

通过群晖Docker搭建azure-openai-proxy,让原先的chatgpt-web能接入Azure OpenAI API。并且支持GPT4模型。
利用免费AI工具创建动画视频教程


你想知道怎么利用免费AI工具,10分钟就可以创建一个动画视频吗?
如何正确高效输入ChatGPT的Prompt 指令

我们怎么能更高效使用AI呢?其中Prompt 指令很重要的一环,下面的Prompt 指令提问技巧希望对大家有帮助。
使用So-VITS-SVC训练属于自己的声音教程


前言:训练出来的声音模型可以在视频、语音或歌曲翻唱使用。 条件: 1、一段自己干净的人声,在安静的环境下录制,最好别低于30分钟,声音文件格式WAV,如果有多个文件,请批量按顺序重命名下文件。 2、一块8G以上显存的独立显卡的电脑。当然也可以用CPU,但那训练速度就慢很多了。 3、电脑上下载好Audio Slicer(音频分割切片)和so-vits-svc 链接:https://pan.baidu.com/s/1glwuY4Zv2mpp05T2uNxzeA提取码:wk5g 操作: 1、新建文件夹,命名为OUT。 2、运行Audio Slicer,拖入需要切片的音频文件,输出文件就选择刚新建的OUT文件夹。然后点start开始。 3、检查切片后的音频文件大小,每段长度最好别超过7秒,如果有发现还有比较长时间的文件,请按下图修改参数后再次切片处理,直到每段长度不超过7秒。 4、解压so-vits-svc,然后把存放切片的OUT文件夹放入so-vits-svc\dataset_raw文件夹下 5、返回so-vits-svc目录,点击”webui.bat“启动。可能需要花几分钟到十几分钟时间。如果没问题等待安装环境后会自动跳出界面,如果没有自动跳出,请按照提示复制IP:端口好,到浏览器里手动打开。 6、点界面上方”训练-识别数据集“会自动识别我们刚放到dataset_raw\OUT文件夹,其他参数不用修改,然后点击下面的数据预处理按钮,开始预处理数据。这个过程需要时间比较长,主要取决于电脑的显卡性能。下面可以看到处理进度,请耐心等待处理完成。 7、预处理完成后清空数据信息,如果没有独立显卡就需要选择CPU来训练,但时间要非常久,要做好思想准备。建议使用NVIDIA的显卡,选择CUDA,这样可以极大提高训练速度。其他只要注意保存步数那,按推荐的设置就可以。然后点击从头开始训练就可以了。 8、训练的时间是非常长的,看显卡性能,需要2-4天左右才能得到比较好的效果,当然,训练可以暂停的,如果被中断,只需再次打开so-vits-svc,点击”继续上次的训练“就可以接着下去训练。 9、查看训练步骤和效果。运行so-vits-svc目录下的tensoboard.bat文件,然后把显示的地址:端口复制到浏览器里打开。然后点上面的AUDIO的页面就可以看到已训练的步骤和试听效果。 10、如果你觉得效果已经可以了,就可以暂停训练了。然后打开推理页面,选择训练好的模型,编码器默认,配置文件选择默认的config.json就可以,然后点下面的加载模型,成功后就可以,上传音频文件,替换原文件的语音或文字转语音。 总之,怎么使用训练好的模型,各位小伙伴就可以发挥各自的聪明才智了。
能在一个窗口里同时操作几个 AI机器人,实现一条指令、多条回复。

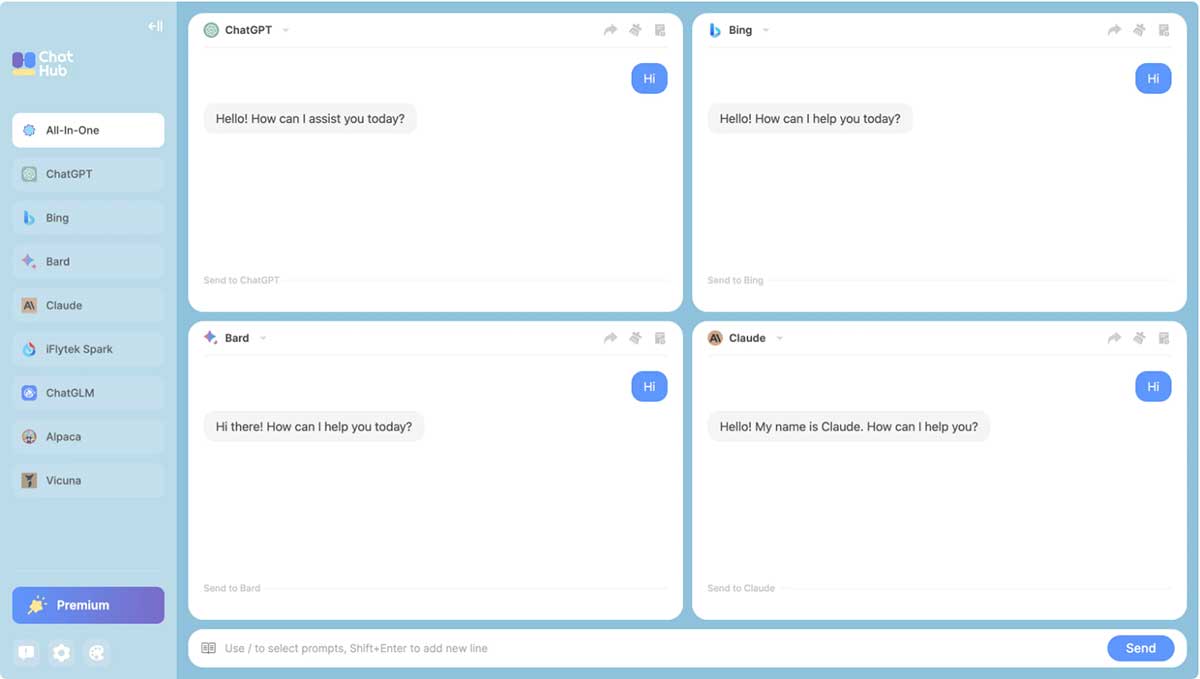
如果你需要经常测试AI性能,又或你需要 推荐用ChatHub客户端,它可以同屏显示多个AI窗口,一次输入,返回多个结果。直接在Chrome和Edge安装好ChatHub插件就能使用。 github地址:https://github.com/chathub-dev/chathub Chrome扩展插件地址:https://chrome.google.com/webstore/detail/chathub-all-in-one-chatbo/iaakpnchhognanibcahlpcplchdfmgma/related?utm_source=chathub.gg
收藏备用:12 个超好用的 AI Chrome 浏览器插件


通过AI,仅需3步,就可以创建出漂亮的图标


步骤 1、打开ChatGPT 并激活插件“Photorealistic” 输入Prompt:“咖啡店的简约标志” 2、 转到 Midjourney 并粘贴第 1 步中的提示之一 等待它生成Logo 选择一个Logo并升级它 3、将大图复制到 Canva,网址:https://www.canva.com/zh_cn/ 按需要添加您的文本
小白用AI-如何根据所需完成的任务使用不同AI工具提高效率和效果


随着AI的蓬勃发展,AI引擎也层出不穷。面对那么多知名的AI工具,我们可以做哪些选择呢?它们都是非常强大的ai工具,但每个又有它们自己擅长的地方。所以我们可以根据自己的任务使用不同AI工具,达到更好的效果和更高的效率。 总结: 很有幸能经历这个AI蓬勃发展这个年代。希望这篇文章对大家能有帮助,同时希望大家都能了解并学会如何驾驭这些非常强大的工具。