

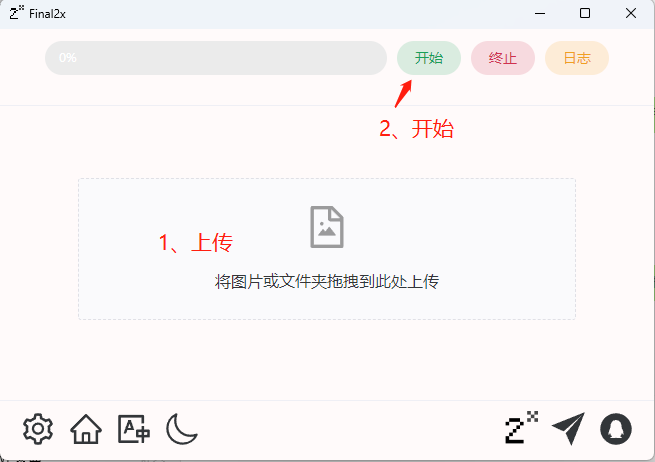
小伙伴有时可能需要把一些老旧模糊,分辨率低下的照片放大并高清处理,让老照片更清楚,分辨率更高。网上虽然也有一些在线的工具,但要么效果不好,或者存在隐私泄露的风险。所以今天我们要说的就是这个可以完全在本机运行的,免费开源的图片放大修复工具Final2x 项目github地址:https://github.com/Tohrusky/Final2x/ 百度网盘:https://pan.baidu.com/s/1seeMyW3jCCwZWehX9zxHiw 提取码: vp4i 1、下载支持相应系统的应用版本,我们下面以Windows版本为例。 2、解压运行Final2x,软件操作十分简单,上传要优化的照片,点击开始就可以了。 3、我们主要来说说左下角的图标,具体看图 4、先点击语言按钮切换你希望的语言界面,然后进入设置界面,鼠标停留在按钮上就会显示相应的提示,注意:如果你有Nvidia独立显卡可以打开TTA,会提升优化效果,否则可能会出现错误。 5、优化后效果展示。 总结:该软件完全开源免费,而且是在本地运行,能防止隐私泄露,而且效果很好,所以推荐使用。
Category: AI
使用So-VITS-SVC训练属于自己的声音教程


前言:训练出来的声音模型可以在视频、语音或歌曲翻唱使用。 条件: 1、一段自己干净的人声,在安静的环境下录制,最好别低于30分钟,声音文件格式WAV,如果有多个文件,请批量按顺序重命名下文件。 2、一块8G以上显存的独立显卡的电脑。当然也可以用CPU,但那训练速度就慢很多了。 3、电脑上下载好Audio Slicer(音频分割切片)和so-vits-svc 链接:https://pan.baidu.com/s/1glwuY4Zv2mpp05T2uNxzeA提取码:wk5g 操作: 1、新建文件夹,命名为OUT。 2、运行Audio Slicer,拖入需要切片的音频文件,输出文件就选择刚新建的OUT文件夹。然后点start开始。 3、检查切片后的音频文件大小,每段长度最好别超过7秒,如果有发现还有比较长时间的文件,请按下图修改参数后再次切片处理,直到每段长度不超过7秒。 4、解压so-vits-svc,然后把存放切片的OUT文件夹放入so-vits-svc\dataset_raw文件夹下 5、返回so-vits-svc目录,点击”webui.bat“启动。可能需要花几分钟到十几分钟时间。如果没问题等待安装环境后会自动跳出界面,如果没有自动跳出,请按照提示复制IP:端口好,到浏览器里手动打开。 6、点界面上方”训练-识别数据集“会自动识别我们刚放到dataset_raw\OUT文件夹,其他参数不用修改,然后点击下面的数据预处理按钮,开始预处理数据。这个过程需要时间比较长,主要取决于电脑的显卡性能。下面可以看到处理进度,请耐心等待处理完成。 7、预处理完成后清空数据信息,如果没有独立显卡就需要选择CPU来训练,但时间要非常久,要做好思想准备。建议使用NVIDIA的显卡,选择CUDA,这样可以极大提高训练速度。其他只要注意保存步数那,按推荐的设置就可以。然后点击从头开始训练就可以了。 8、训练的时间是非常长的,看显卡性能,需要2-4天左右才能得到比较好的效果,当然,训练可以暂停的,如果被中断,只需再次打开so-vits-svc,点击”继续上次的训练“就可以接着下去训练。 9、查看训练步骤和效果。运行so-vits-svc目录下的tensoboard.bat文件,然后把显示的地址:端口复制到浏览器里打开。然后点上面的AUDIO的页面就可以看到已训练的步骤和试听效果。 10、如果你觉得效果已经可以了,就可以暂停训练了。然后打开推理页面,选择训练好的模型,编码器默认,配置文件选择默认的config.json就可以,然后点下面的加载模型,成功后就可以,上传音频文件,替换原文件的语音或文字转语音。 总之,怎么使用训练好的模型,各位小伙伴就可以发挥各自的聪明才智了。
一键生成最近很火的美化二维码教程


这应该是目前最简单的方法,不用搭任何环境。 1、先用草料二维码生成器,生成需要的普通二维码,注意:就算是个人的微信二维码也建议用草料二维码再重新生成过。草料二维码生成器:https://cli.im/ 2、打开https://huggingface.co/spaces/huggingface-projects/QR-code-AI-art-generator。上传刚生成的二维码图。 3、在下面Prompt那里写上提示词,注意要用英文。再点击最下面的RUN,大概等一分钟左右就可以看到美化过的二维码了。如果不满意请再修改Prompt重新生成。 快去生成一个让朋友们惊艳一下吧!
OpenAI 官方版 GPT 最佳实践指南


OpenAI官方推荐6个使用技巧
1、撰写清晰的 Prompt
2、提供参考文本
3、将复杂的任务拆分子任务
4、给 GPT 时间来思考
5、集成外部工具
6、给 GPT 结果进行测试或评估
换脸神器:roop在Google colab安装与使用教程

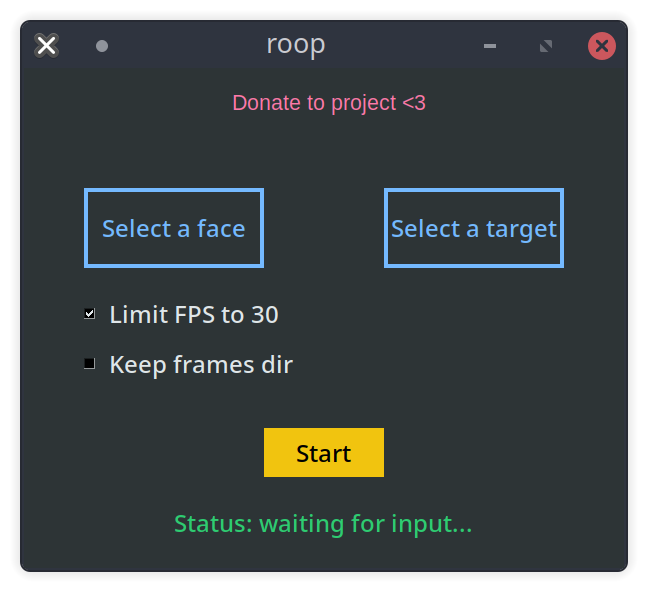
前言: roop是一款相对简单易用,不用经过大量训练就能达到很不错的换脸效果的应用。 roop项目地圵:https://github.com/s0md3v/roop 它可以支持GPU、CPU及Google colab下运行。GPU、CPU下运行都需在电脑上安装环境及设置,对小白来说还是有一定门槛。所以这篇文章主要讨论Google colab安装与使用roop教程,优点是非常简单,而且速度飞快。缺点是对国内网络有特殊要求。 正文: 1、运行roop-ai-colab脚本,https://colab.research.google.com/drive/1GQ_6Sc2ipDMEX2EHsUW_ALXXrJ12yICJ?usp=sharing。在colab窗口右上方点连接,等待启动。 2、点右下更改运行时的类型-选择GPU-保存,如果默认就是,无需操作,直接退出设置。 3、先执行上面的代码,下载安装,需要等待安装完成。 4、点击左侧roop的目录,点击上传,上传你需要替换的视频,和一张人脸图片 5、修改第二条命令里的三个文件名,分别是上传的图片、视频的文件名,第3个是输出的文件名,没问题后点运行。耐心等待视频合成完毕后就可以下载到电脑上了。 总结: roop是一款非常易用的开源换脸应用,而且还支持GPU、CPU本地运行,私密性也有保证,但本地配置相对比较麻烦,如果您只是临时使用下,或电脑配置实在太低,可以采用这个方式运行。非常方便
能在一个窗口里同时操作几个 AI机器人,实现一条指令、多条回复。

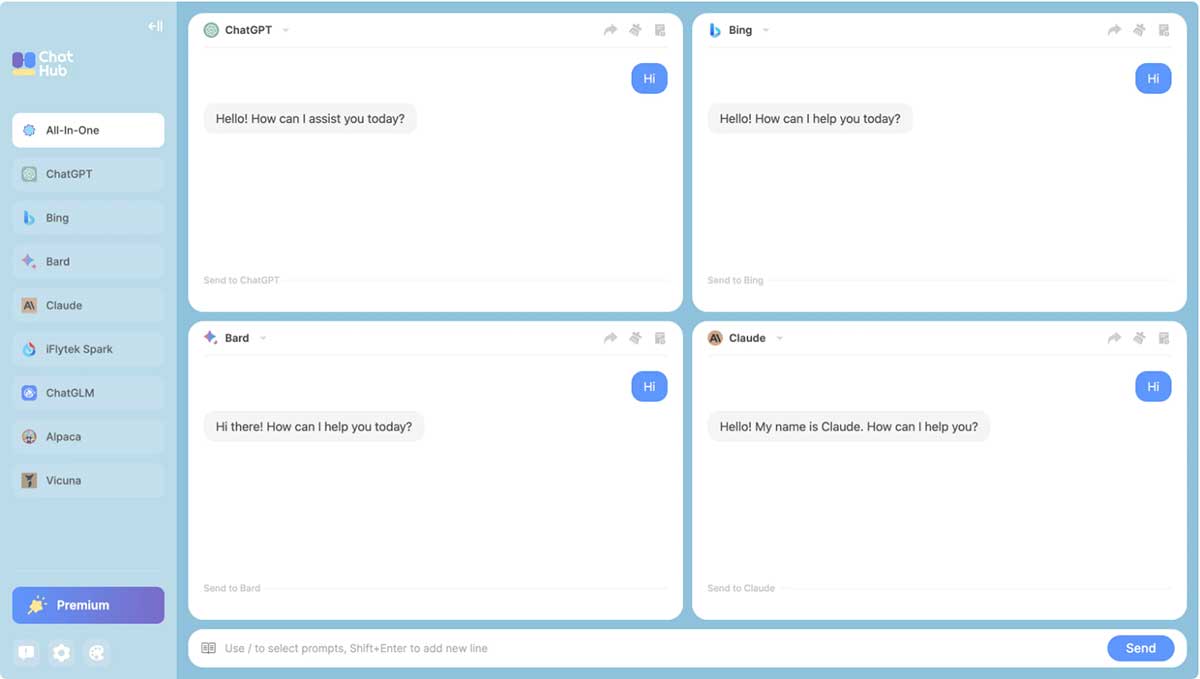
如果你需要经常测试AI性能,又或你需要 推荐用ChatHub客户端,它可以同屏显示多个AI窗口,一次输入,返回多个结果。直接在Chrome和Edge安装好ChatHub插件就能使用。 github地址:https://github.com/chathub-dev/chathub Chrome扩展插件地址:https://chrome.google.com/webstore/detail/chathub-all-in-one-chatbo/iaakpnchhognanibcahlpcplchdfmgma/related?utm_source=chathub.gg
收藏备用:12 个超好用的 AI Chrome 浏览器插件


通过AI,仅需3步,就可以创建出漂亮的图标


步骤 1、打开ChatGPT 并激活插件“Photorealistic” 输入Prompt:“咖啡店的简约标志” 2、 转到 Midjourney 并粘贴第 1 步中的提示之一 等待它生成Logo 选择一个Logo并升级它 3、将大图复制到 Canva,网址:https://www.canva.com/zh_cn/ 按需要添加您的文本
免费创建 AI 图像,并用GPT提高图像生成效果

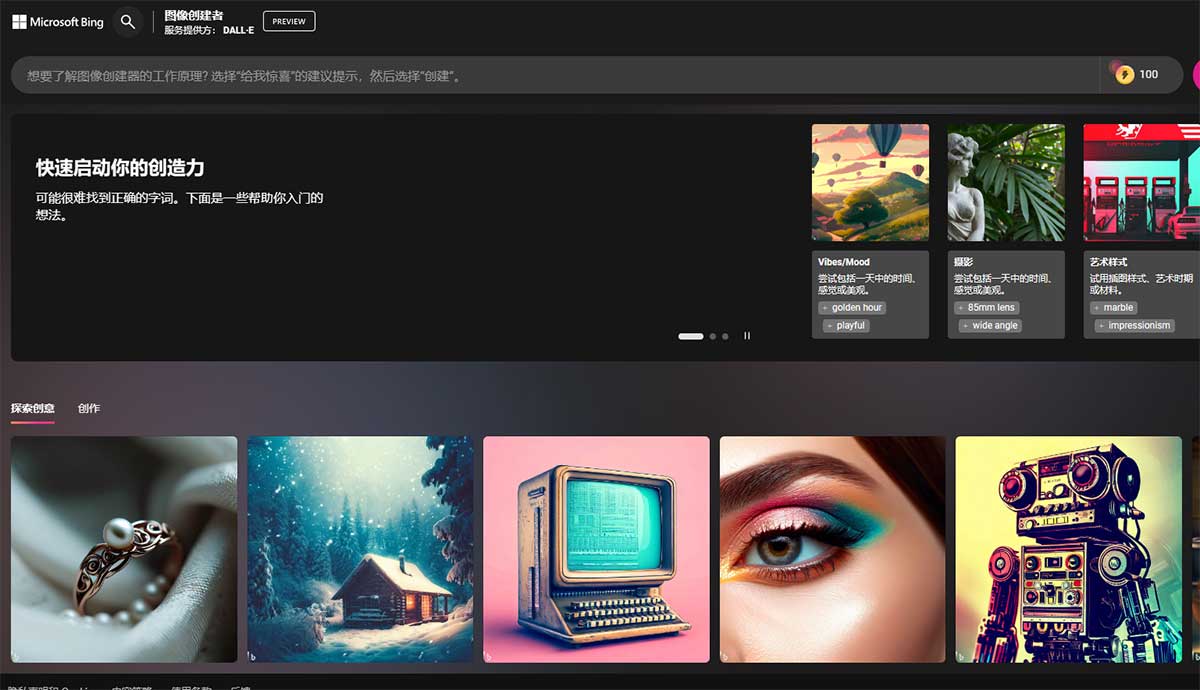
1、前往 Bing Image Creator 网址:https://cn.bing.com/create 然后使用 Microsoft 帐户登录。 2、输入您的提示词,在输入框中描述您要生成的图像,然后单击“创建”。 3、想要好的效果就需要好的提示词,您可以参考借鉴各种提示词网站,也可以让chatgpt来帮你。 你可以告诉chatgpt:我希望你充当 Midjourney 人工智能项目的提示词生成器.你的工作是提供详细而富有创意的描述,从人工智能中激发出独特而有趣的图像。请记住,人工智能能够理解各种语言,并能够解释抽象概念,所以请尽可能富有想象力和描述性.例如,你可以描述一个未来城市的场景,或者一个充满奇怪生物的超现实景观。你的描述越详细、越富有想象力,所产生的图像就越有趣。这是你的第一个提示:”一片野花延伸到眼睛所能看到的地方,每一朵都有不同的颜色和形状。“ 4、等待图像生成完毕,点击想要保存的图像,点击放大,下载保存。
小白用AI-如何根据所需完成的任务使用不同AI工具提高效率和效果


随着AI的蓬勃发展,AI引擎也层出不穷。面对那么多知名的AI工具,我们可以做哪些选择呢?它们都是非常强大的ai工具,但每个又有它们自己擅长的地方。所以我们可以根据自己的任务使用不同AI工具,达到更好的效果和更高的效率。 总结: 很有幸能经历这个AI蓬勃发展这个年代。希望这篇文章对大家能有帮助,同时希望大家都能了解并学会如何驾驭这些非常强大的工具。
Free and open source, completely offline stand-alone audio and video to text generation subtitles software WhisperDesktop

Software Github address:https://github.com/Const-me/Whisper Download Address:https://github.com/Const-me/Whisper/releases/tag/1.11.0 For Windows systems, download WhisperDesktop.zip and you’re done! I. Introduction: WhisperDesktop is based on the Whisper speech-to-text technology launched by OpenAI around early 2023. Through AI recognition technology, it can not only generate text quickly and correctly but also perform real-time translation. The advantage is that it is free and… Continue reading Free and open source, completely offline stand-alone audio and video to text generation subtitles software WhisperDesktop
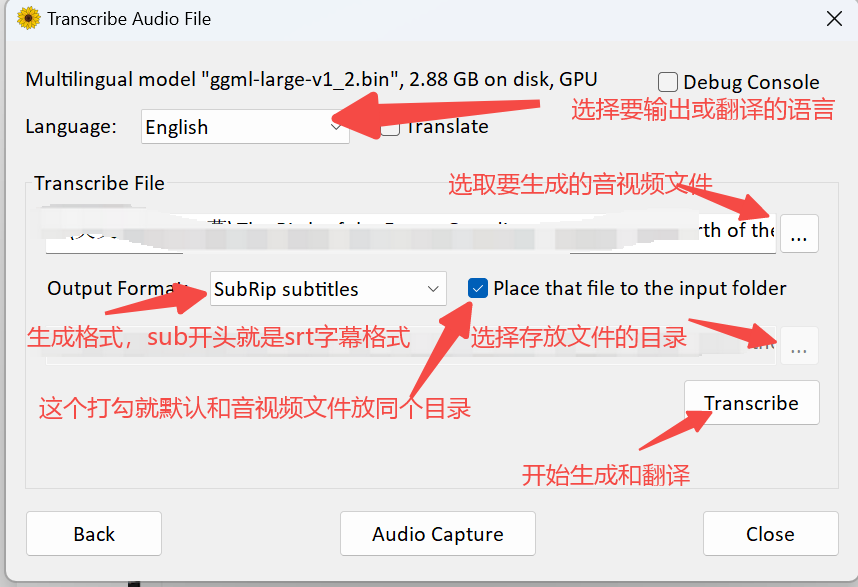
免费开源,可完全离线单机运行的音视频转文字生成字幕的软件WhisperDesktop
软件开源Github地址:https://github.com/Const-me/Whisper 下载地址:https://github.com/Const-me/Whisper/releases/tag/1.11.0 Windows系统就下载WhisperDesktop.zip这个压缩包就可以了,如果不方便打不开的话,我也会把文件上传到网盘上,需要的到文章底部下载链接下载。 一、简介: WhisperDesktop是基于OpenAI在2023年初左右推出的Whisper语音转文字技术,通过AI识别技术,它不仅能快速地、正确地生成文字还能进行实时翻译。优点是免费,可离线单机使用,不用上传任何数据,缺点是需要通过python命令行运行,对小白用户实在有点不友好。所以才会出现许多套壳的应用,而WhisperDesktop正是其中一款比较方便的应用。 二、使用方法: 1、除了下载WhisperDesktop软件 ,还要下载一个Whisper模型,下载网址:https://huggingface.co/datasets/ggerganov/whisper.cpp/tree/main。开放者建议ggml-medium.bin 这个版本的模型就可以。点击进入相应的模型链接,然后点左边的download下载。 2、把软件和都解压后,运行WhisperDesktop.exe。第一次运行需要选择模型,选择你存放模型的目录下的模型即可。 3、具体操作界面看下图说明: 4、Audio Capture(音频采集),软件还支持实时音频采集生成文字,具体操作看下图: 5、转换生成速度取决于你的电脑配置,一般有独立显卡的话,转换生成一个6分钟左右的视频不会超过1分半钟(仅供参考)。 6、一般情况下Whisper转换的识别率和准确率已经非常高了(95%以上),但还是会受到模型的影响,具体可以自行测试,你也可以自己打开转换后的字幕文件自行校对修改。 三、总结: WhisperDesktop是一个免费软件,操作简单,不用上传任何东西到云端,也没有任何限制,再加上不错的识别率和生成速度,所以是值得推荐给有需要语音转文字的朋友使用的。