


硬件要求: 安装使用教程: 1、下载ollama 客户端【点击下载对应系统版本的客户端】 2、下载安装完成后运行CMD命令下载安装对于模型使用 普通7B版 安装指令: 7B的全量版本: 2B轻量版: 3、耐心等待模型下载完成即可在cmd里直接使用,关闭后下次可重新打开cmd命令,运行上面命令使用,已下载的模型不会重复下载。 优点:
Category: AI
不用5分钟,就能搭建一个在本地使用的ChatGPT


我们只要自己申请个OpenAI KEY,通过python,10几行代码,就能在本地运行ChatGPT,不用搭建任何服务器。 1、下载安装python 2、申请API Key 先去openai网站注册一个账号,然后登陆选择API,生成自己的API Key,复制保存下来备用 3、设置一个Windows系统环境变量 打开设置-系统-高级系统设置-环境变量-系统变量-新建一个变量 变量名:OPENAI_API_KEY 注意:一定要大写和下划线,不能搞错。 变量值:就是前面保存的API Key 5,添加代码。 可以用系统的文本编辑器,把下面代码复制到文本编辑器,然后另存为.py的python文件即可 5、运行代码 运行CMD命令-输入“python 文件名.py”运行文件即可
DFLive AI实时换脸系统!可用于OBS和YY直播,没显卡CPU也能用!软件+人脸模型下载!

声明,本文章和软件仅作AI人工智能技术的讨论研究与分享,请勿用于非法行为。一切后果由使用者自行承担。 简单说明: 整合包,解压运行。默认带2个人脸模型,如需更多模型,先下载模型文件,拷贝到模型目录内,然后在软件里选择对应模型即可。 下载完请先看说明,2个运行文件都是压缩包,DFLive_N-0709是N卡使用,N卡以外,或只用CPU使用DFLive_DX12-0709压缩包。 【百度网盘下载】提取码: h94u
不用独立显卡,能在本地运行多种开源大模型的Ai工具GPT4All

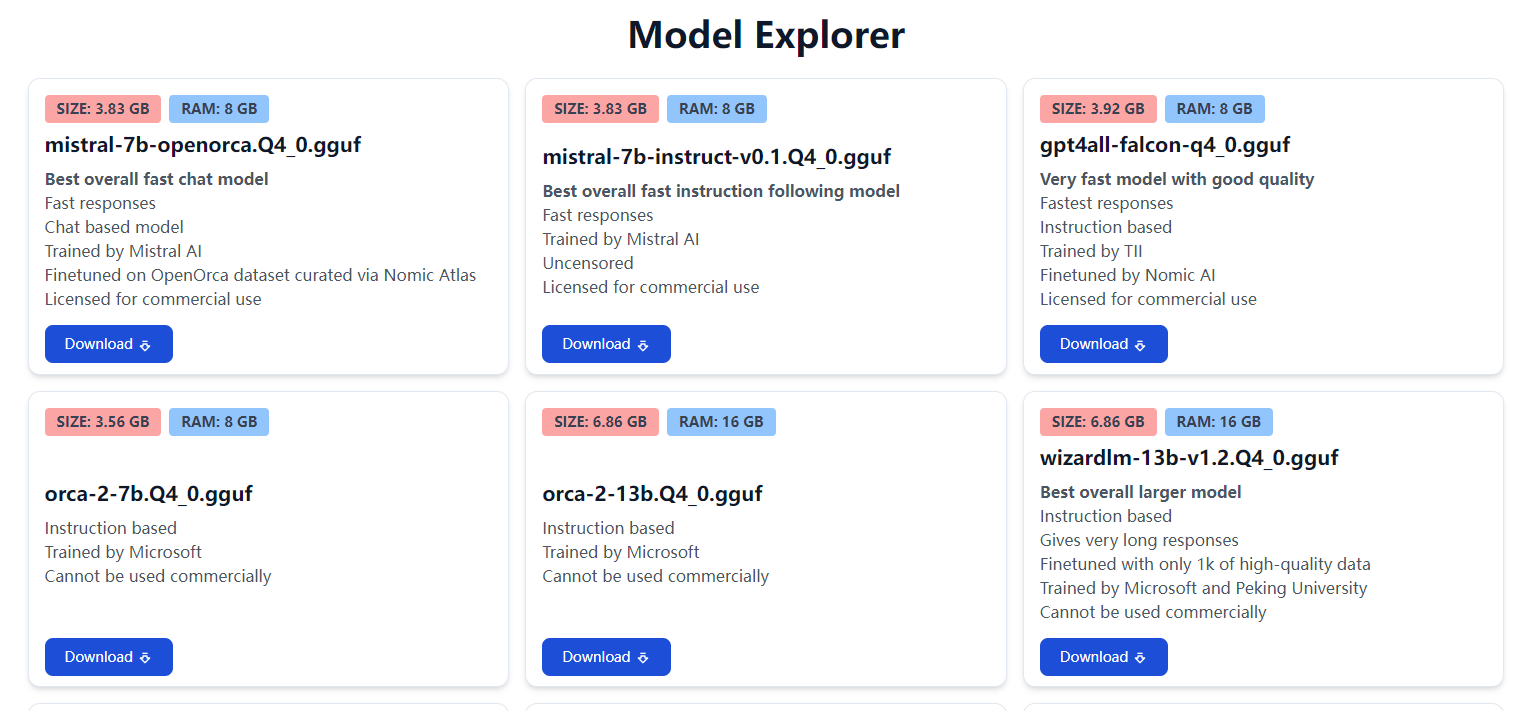
什么是GPT4All? GPT4All是一个能开源的、无需 GPU 或互联网、就能免费使用、具有隐私保障的聊天机器人。它可以可在消费级 CPU 和任何 GPU 上本地运行的大型语言模型,比如说最新的Mistral 7b 基础模型。请注意,您的 CPU 需要支持AVX 或 AVX2 指令。 【项目github地址】【官方网站】 安装: 1、去官网下载对应系统GPT4All安装程序,我们以Windows系统为例【官网下载Windows客户端】 2、【官方网站】下载想用的大模型数据,建议mistral-7b的大模型。如果下载不了,我们也已经把Windows安装程序和mistral-7b-openorca.Q4_0和gpt4all-falcon-q4_0.gguf 两个大模型一上传到网盘。【百度网盘下载】 3、下载完成后运行安装程序进行安装即可,很简单就细说了。 使用: 1、安装完成后,运行GPT4All,点击右上角设置(齿轮)- Application设置下模型下载存放的目录即可。 2、关闭GPT4All后重新进入,就可以看到已经下载好的模型,选择想要使用的模型,在下面的聊天框里就可以和AI愉快的玩耍了。 经过简单使用,总结下优缺点: 缺点: 1、以最新Mistral 7b 基础模型模型为例,经过简单的使用,其英文方面能力远大于中文能力。 2、相对于OpenAI GPT4等商业大模型还有较大差距,并不能完全替代ChatGPT,但已经是能用状态。 3、就算不用独立显卡,对CPU还是有一定要求的,就算是支持AVX 或 AVX2 指令的cpu,如果性能比较低,那速度也会变的非常感人。 优点: 1、在可用状态下完全免费 2、支持多种开源大模型 3、可以本地运行,在隐私方面将得到更好的保障 4、使用门槛较低,大部分主流配置的电脑和系统都可以运行。 5、各种开源大模型虽说目前还远远不能和GPT4等顶尖的AI对比,但它对打破少数机构对新科技的垄断,提高竞争,对普通大众和技术发展来说都是很有帮助的。
使用群晖docker搭建开源的高性能聊天机器人Lobe Chat,含使用教程


一款私人 ChatGPT/LLM 网页应用程序。适合自己及家人使用。开源的高性能聊天机器人框架,界面美观,支持语音合成、多模态、可扩展的。部署和使用教程。
开源克隆声音工具,将文字或其他语音转成该音色

一、软件说明 这个声音克隆工具,可使用任何人类音色,将一段文字合成为使用该音色说话的声音,或者将一个声音使用该音色转换为另一个声音。 使用非常简单,没有N卡GPU也可以使用,下载预编译版本,双击 app.exe 打开一个web界面,鼠标点点就能用。 支持 中文、英文、日语、韩语 4种语言,可在线从麦克风录制声音。 为保证合成效果,建议录制时长5秒到20秒,发音清晰准确,不要存在背景噪声。 英文效果比中文效果好。 二、使用方法 1、下载预编译版,适用于window 10/11(已含文字到语音模型,语音到语音模型需单独下载),Mac下请拉取源码自行编译。 【github下载】【百度网盘下载:提取码: hadx】 2、解压后进入解压目录,双击 start.bat ,等待自动打开web窗口。 3、输入文字或者上传想转换的音频文件,然后录制或从本地上传一段音色文件,开始转换 4、预编译版仅支持CPU,只包含文字到语音模型,如果需要语音到语音功能,即上传一个音频文件,然后将该音频转换为使用选定音色的另一个音频,需单独下载语音到语音(speech-to-speech)模型,然后放到和app.exe同级的tts文件夹中。 speech-to-speech模型下载:【百度网盘:提取码: g3w8】【github下载】 三、常见问题 1、启动后需要冷加载模型,会消耗一些时间,请耐心等待显示出http://127.0.0.1:9988, 并自动打开浏览器页面后,稍等两三分钟后再进行转换 2、如果打开的cmd窗口很久不动,需要在上面按下回车才继续输出,请在cmd左上角图标上单击,选择“属性”,然后取消“快速编辑”和“插入模式”的复选框 四、源码部署,以window为例
基于AI,能无损分辨率去除图片/视频硬字幕、水印,无需申请第三方API,本地运行的软件。

一、它能做什么? video-subtitle-remover (VSR) 是一款基于AI技术,它能够通过AI算法模型,对去除字幕文本的区域进行填充(非相邻像素填充与马赛克去除),无损分辨率去除视频中的硬字幕,并支持自定义字幕位置(传入位置)和自动去除所有字幕的软件(不传入位置)。 项目开源地址:https://github.com/YaoFANGUK/video-subtitle-remover 二、硬件要求: GPU:GTX 1060或以上显卡(目前暂不支持Nvidia以外的显卡) CPU: 支持AVX指令集 三、使用说明:直接下载压缩包解压运行,仅支持Nvidia显卡。 Windows GPU版本v1.0.0(GPU): 百度网盘: vsr_windows_gpu_v1.0.0.7z 提取码:vsr1 Google Drive: vsr_windows_gpu_v1.0.0.7z
无需配置,无需安装,解压即用的AI人脸替换工具


无需配置,无需安装,解压即用。支持图片、视频人脸替换,支持支持CPU和GPU解码,而且效果还不错的AI人脸替换工具软件。
如何使用 DALL-E 3 创建 99.9% 一致风格形象的系列图片


使用 DALL-E 3 创建 99.9% 一致风格形象的系列图片。从单色插图到高级电影镜头能保持99.9% 一致风格形象的方法。
用群晖的Docker搭建可以支持Microsoft Azure的ChatGPT,并支持ChatGPT 4模式。

通过群晖Docker搭建azure-openai-proxy,让原先的chatgpt-web能接入Azure OpenAI API。并且支持GPT4模型。
利用免费AI工具创建动画视频教程


你想知道怎么利用免费AI工具,10分钟就可以创建一个动画视频吗?
如何正确高效输入ChatGPT的Prompt 指令

我们怎么能更高效使用AI呢?其中Prompt 指令很重要的一环,下面的Prompt 指令提问技巧希望对大家有帮助。