
前言:训练出来的声音模型可以在视频、语音或歌曲翻唱使用。
条件:
1、一段自己干净的人声,在安静的环境下录制,最好别低于30分钟,声音文件格式WAV,如果有多个文件,请批量按顺序重命名下文件。
2、一块8G以上显存的独立显卡的电脑。当然也可以用CPU,但那训练速度就慢很多了。
3、电脑上下载好Audio Slicer(音频分割切片)和so-vits-svc
链接:https://pan.baidu.com/s/1glwuY4Zv2mpp05T2uNxzeA
提取码:wk5g
操作:
1、新建文件夹,命名为OUT。
2、运行Audio Slicer,拖入需要切片的音频文件,输出文件就选择刚新建的OUT文件夹。然后点start开始。
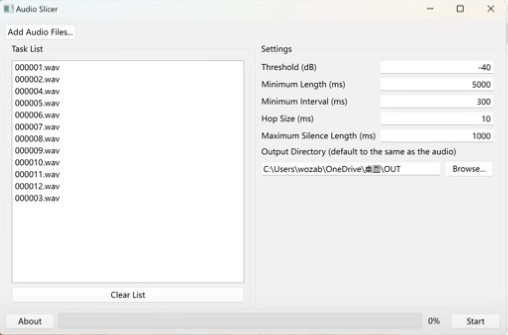
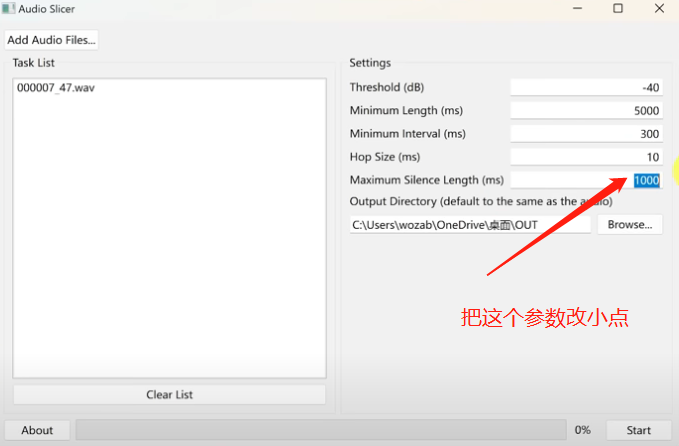
3、检查切片后的音频文件大小,每段长度最好别超过7秒,如果有发现还有比较长时间的文件,请按下图修改参数后再次切片处理,直到每段长度不超过7秒。
4、解压so-vits-svc,然后把存放切片的OUT文件夹放入so-vits-svc\dataset_raw文件夹下
5、返回so-vits-svc目录,点击”webui.bat“启动。可能需要花几分钟到十几分钟时间。如果没问题等待安装环境后会自动跳出界面,如果没有自动跳出,请按照提示复制IP:端口好,到浏览器里手动打开。
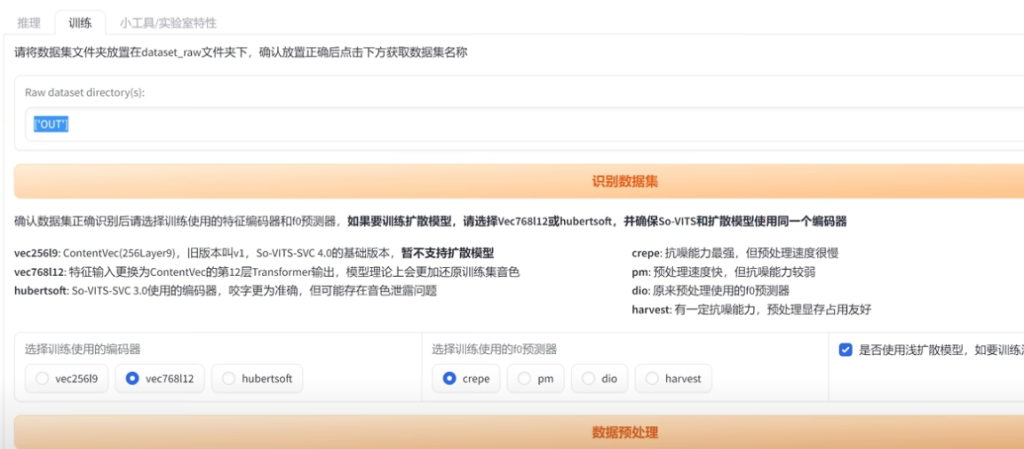
6、点界面上方”训练-识别数据集“会自动识别我们刚放到dataset_raw\OUT文件夹,其他参数不用修改,然后点击下面的数据预处理按钮,开始预处理数据。这个过程需要时间比较长,主要取决于电脑的显卡性能。下面可以看到处理进度,请耐心等待处理完成。
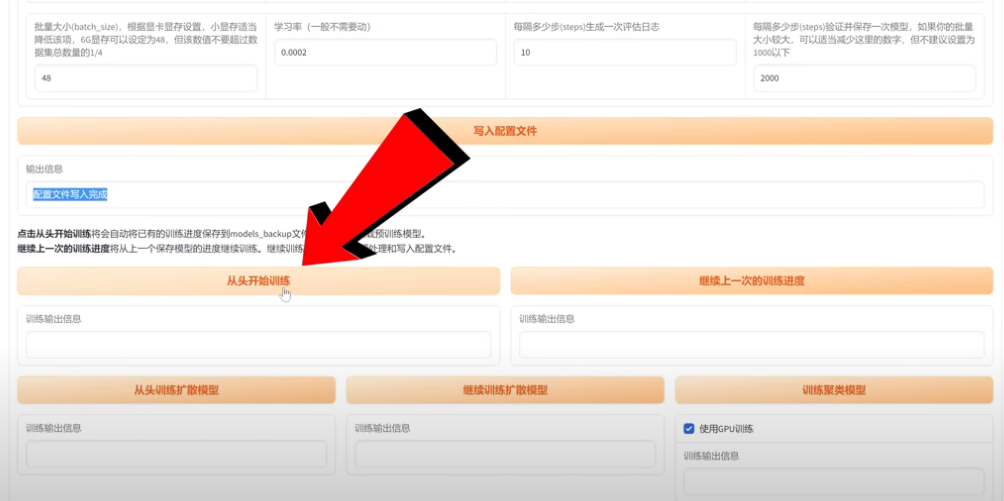
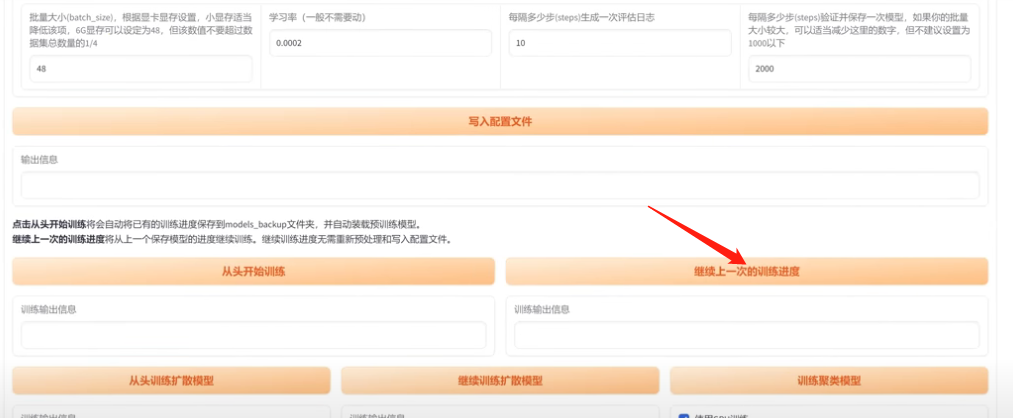
7、预处理完成后清空数据信息,如果没有独立显卡就需要选择CPU来训练,但时间要非常久,要做好思想准备。建议使用NVIDIA的显卡,选择CUDA,这样可以极大提高训练速度。其他只要注意保存步数那,按推荐的设置就可以。然后点击从头开始训练就可以了。
8、训练的时间是非常长的,看显卡性能,需要2-4天左右才能得到比较好的效果,当然,训练可以暂停的,如果被中断,只需再次打开so-vits-svc,点击”继续上次的训练“就可以接着下去训练。
9、查看训练步骤和效果。运行so-vits-svc目录下的tensoboard.bat文件,然后把显示的地址:端口复制到浏览器里打开。然后点上面的AUDIO的页面就可以看到已训练的步骤和试听效果。
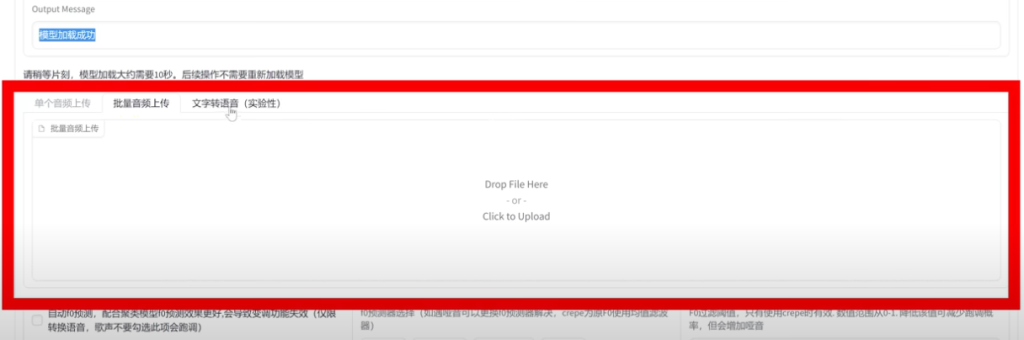
10、如果你觉得效果已经可以了,就可以暂停训练了。然后打开推理页面,选择训练好的模型,编码器默认,配置文件选择默认的config.json就可以,然后点下面的加载模型,成功后就可以,上传音频文件,替换原文件的语音或文字转语音。
总之,怎么使用训练好的模型,各位小伙伴就可以发挥各自的聪明才智了。

